 b.stefanuk.ca
b.stefanuk.caComponents Distributed Systems
Terminology
- Availability. A high-availability system means that it remains operational and responsive to requests, even if one or more nodes are down.
- Fault tolerance. Fault tolerance mechanisms include replication and error recovery. They contribute to high-availability by mitigating the impacts of hardware or software failures.
- Replication. Refers to the creation of multiple instances of the same service. This can improve fault tolerance and performance by supporting parallelism.
- Data Consistency. Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful.’
- Be familiar with concepts of eventual consistency (will eventually resolve to a consistent state) and strong consistency (consistency guarantees).
- Replication. Refers to the creation of multiple instances of the same service. This can improve fault tolerance and performance by supporting parallelism.
- Scalability is the ability to handle an increased workload by repeatedly applying a cost-effective strategy for extending a system's capacity.
- Horizontal scaling. Adding more servers.
- Vertical scaling. Adding more power (CPU, RAM, Storage) to existing servers.
- Performance. Consider aspects of latency.
- Sharding. A data storage technique whereby a large data-store is broken up into many smaller data stores.
- Caching. A strategy to store frequently requests resources for quick access can reduce latency. Consider aspects of cache invalidation and refresh policies.
- Durability. If message queuing is involved, consider persistence and durability (see Networking Acronyms & Terminology)
- Partition tolerance. Relates to the 'partitioning' or segmentation of a network when a failure occurs, such that groups of nodes can communicate with each other, but not with the total set of nodes. Partition tolerance therefore refers to the ability for a system to remain functional despite being unable to contact nodes in other partitions.
CAP Theorem
The CAP theorem [states] that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (CAP).
Storage Systems
As it turns out, distributed storage systems cover a vast array of use cases and serves as a valuable and flexible abstraction for many distributed systems requirements.
Case study: Google Filesystem
NoSQL databases are ideal for distributed network applications. Unlike their vertically scalable SQL (relational) counterparts, NoSQL databases are horizontally scalable and distributed by design—they can rapidly scale across a growing network consisting of multiple interconnected nodes.
RPC
RPC pros and cons
| Pros ✅ | Cons ❌ |
|---|---|
| Data ownership | Tight system coupling: If application A needs to invoke a function on application B in a single logical unit of work per request, and if application B is unavailable, then you are tightly coupled to the system. |
| Great for external system integration: integration with systems across a firewall | Async communications is difficult: No true queue mechanism and no guaranteed delivery mechanisms. |
| Mature framework and tools (especially re. REST APIs) | Broadcast capabilities are difficult: One to many messaging patterns |
What is an RPC?
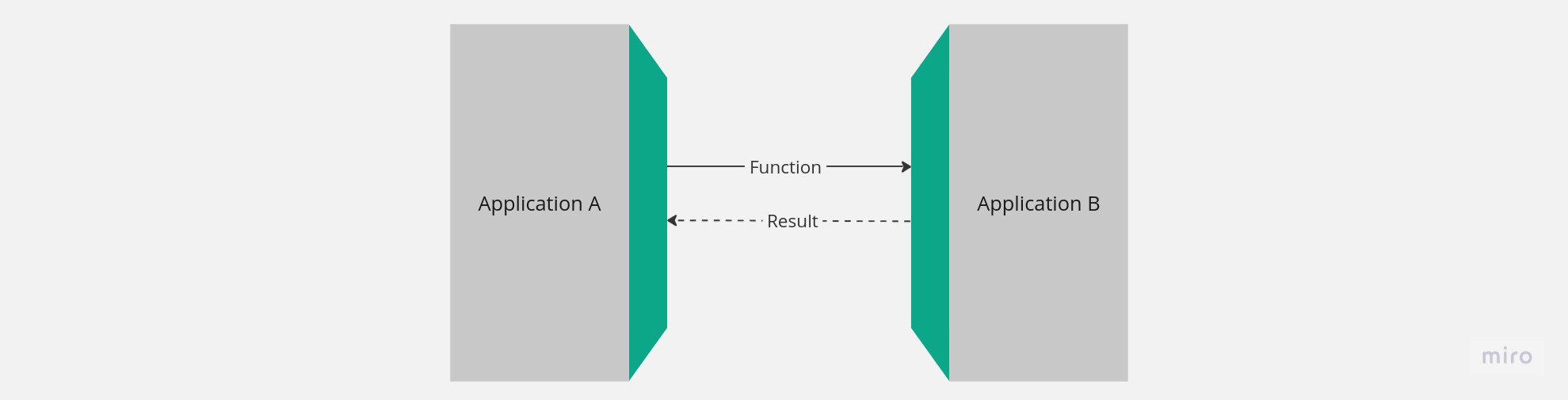
Think of an RPC as a function call. Take the scenario below.
App A sends executes a function on App B by sending it message with all the items required to execute said function. Some time later, a message is returned to it containing the result of the function. Formally, App A establishes a contract with App B that will eventually be fulfilled. Thus, an RPC is a function/procedure call on a network connected device.
gRPC uses protocol buffers (aka protobuf), which is a strongly typed schema definitions with data access classes generated. Profobuf is estimated 5x faster than json
gRPC
When to use gRPC
- MUST WATCH: https://www.youtube.com/watch?v=4SuFtQV8RCk-
- Don't use
- In particular, don't use service-to-service comms when it's client originated.
- Using gRPC for s-to-s comms when the request is broker originated it okay.
- Do use gRPC for view composition infrastructure, e.g., frontend request to backend over REST API (or grpc-web), backend then initiates gRPC request to various services to, structuring a view of some data.
- Avoid using gRPC for direct, service to service communication that's client originated. Else you'll end up with a highly coupled system that's effectively a monolith.
GRPC is built ontop of HTTP/2
- Must watch video on gRPC: https://www.youtube.com/watch?v=ctzM1osMmrI&list=PLdsOZAx8I5umhnn5LLTNJbFgwA3xbycar&index=112 Interservice communication system of choice between microservices in datacenters. Language agnostic.
"RPC APIs allow developers to call remote functions in external servers as if they were local to their software. For example, you can add chat functionality to your application by remotely calling messaging functions on another chat application." -- AWS - RPC vs REST (must read)
Tips
Message Queuing
With message queuing your'e not communcating to another application, you're communication to a queue, high level of system abstraction. Watch this video on messaging for a phenomenal refresher.
Options.
- AMQP with RabbitMQ
- SNS (Amazon Simple Notification Service)
- SQS (Amazon Simple Queue Service)
- MQTT (MQ Telemetry Transport) - works really well when talking between machines and equipment
- STOMP
| Pros ✅ | Cons ❌ |
|---|---|
| Highly decoupled systems | Integration beyond a firewall is hard because we don't have HTTP with messaging |
| Guaranteed delivery | Implementation complexity |
| Async communications | Testing complexity |
| Broadcast capabilities | Cross-platform standards |
| Ease of scalability | Async error handling |