b.stefanuk.ca
b.stefanuk.caNeeds refactor
System Design Interview
Steps for success
- Make a problem statement
- Define functional requirements.
- Define non-functional requirements.
- Clarify the problem and requirements upfront. The problems are usually deliberately vague.
Tip
- For functional requirements we want to define APIs, a set of inputs and outputs (functions) that the system supports.
- Non-functional requirements aren't always easy to define. Think of...
- Availability
- Scalablility
- Performance
- Maintainability
- Testability
- If a database is involved, consider persistence and durability (seeNetworking Acronyms & Terminology)
- May also include edge requirements:
- Standards/compliance requirements
- Compatibility requirements
- The interviewer is your friend. Start approaching any design problem with small and simple steps. Demonstrate progress and your ability to simplify problems.
Tip
The pattern with a load balancer, frontend system, database, and database adapter/cache service is extremely common and can be applied to many system design interview questions.
Distributed Cache
Reference: https://www.youtube.com/watch?v=iuqZvajTOyA
- When you think of Cache, think of a Hash Map.
- Eviction, think of least recently used; therefore you need another data structure: doubly linked list
- Least Recently Used (LRU) cache eviction algorithm is a very common interview question.
- If you make each host store only a chunk of data, this is called a shard
- When data is sharded, we can store much more data in the cache
Architectures
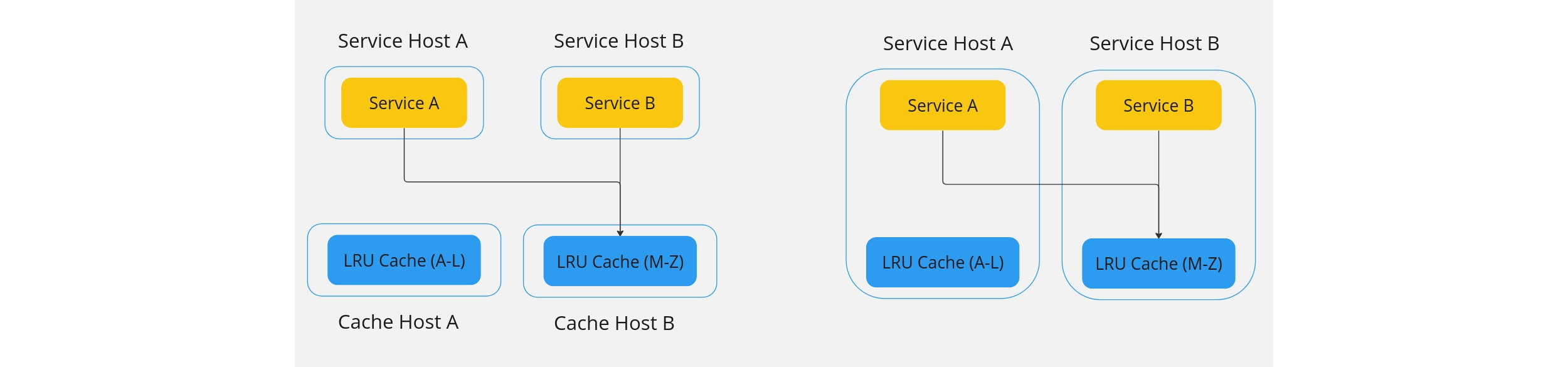
- Dedicated cache cluster: Cache clusters are on distributed servers and thus can be used by multiple services. Harder to implement, but more flexibility.
- Co-located (local) cache: No extra hardware or operational costs, scales with the service
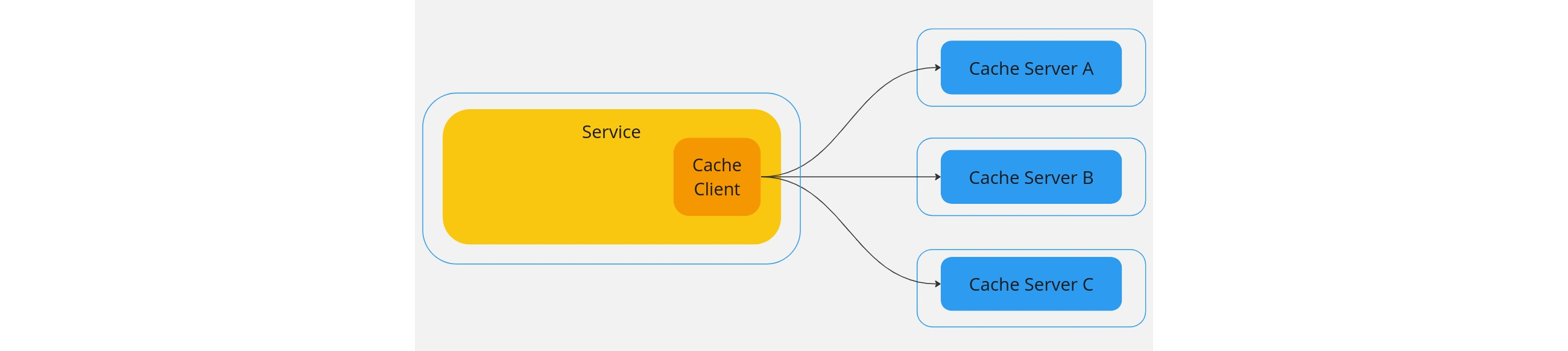
The Cache Client
A cache client, which lives inside the primary service, is responsible for hash calculations, and thereby choosing a cache host.
Tip
Use consistent hashing: map each entity to a point on the circle. It is much better than mod hashing.
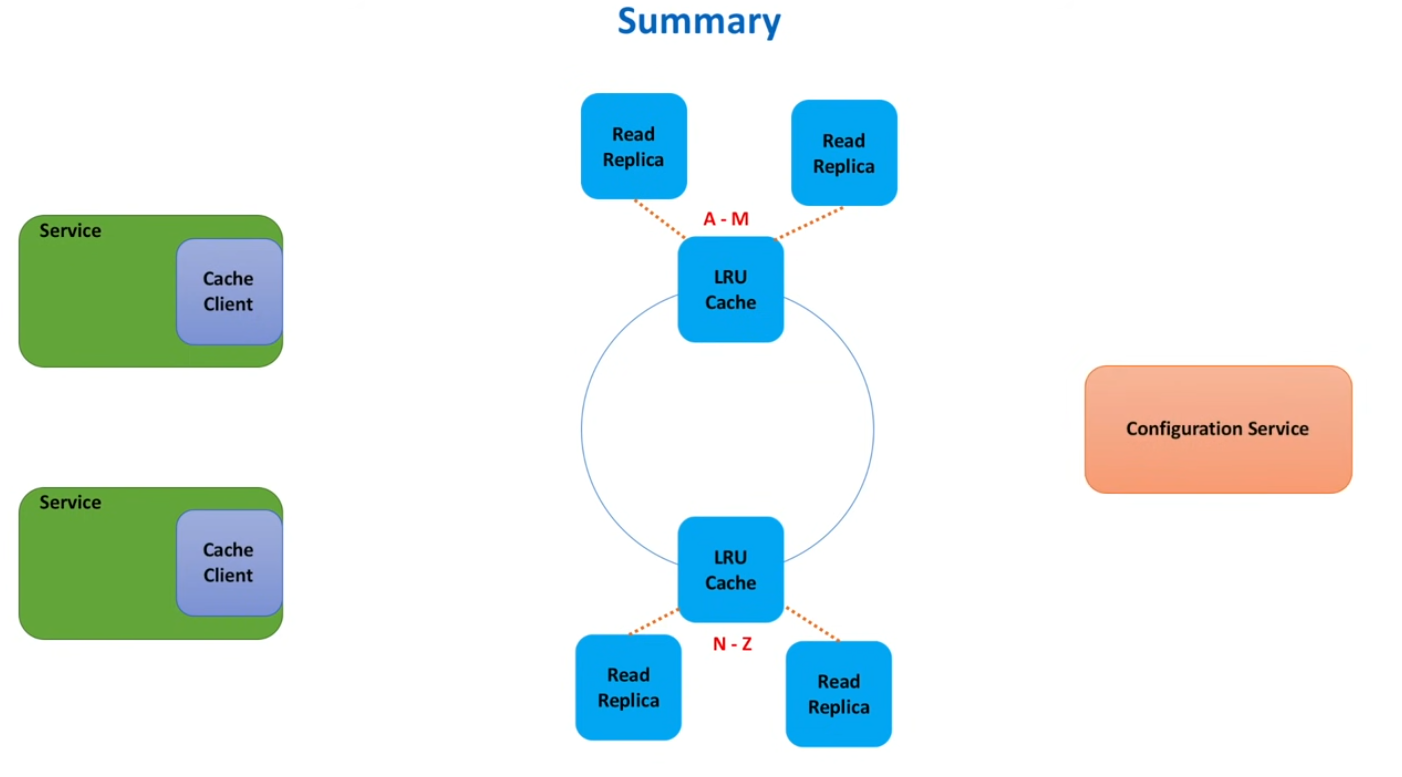
Storing Cache Server Addresses
- Easy but not flexible: Store a list of cache server hosts in a file and use configuration management (e.g. Ansible) to deploy to every service.
- Medium difficulty, more flexible: Service hosts use a shared file (e.g. S3) that runs with a daemon to query the shared storage periodically.
- Harder implementation, but more scalable. Use a configuration service, e.g., Apache Zoopkeeper, HashiCorp Consul, etc.
.4d7605d2.jpg)
Recall non-functional requirements.
- You can improve availability my doing database replication
- Another problem you can identify is the hot-shard problem
- Consistency - some clients may send data to different cache servers if one goes down
- Data expiration - some data items may become stale and add a time to live
- We can to pro-active expiration (on a quasi-random periodic loop)
- We can do reactive expiration so only when a data point is queried we expire it or not
- Security - firewalls, etc
- Monitoring and logging - number of faults, latency, memory utilization, CPU load averages
- Consistent hashing: potential problems include domino effect and uneven loading of keys among cache servers.
Rate Limiting OR Throttling
Reference: https://www.youtube.com/watch?v=FU4WlwfS3G0
Problem statement: Limit the amount of requests that are processed in a given amount of time.
Almost all public APIs implement a rate limiter. These are use to resolve the noisy neighbour problem where one client uses too much shared resources on a service host, e.g., CPU, memory, disk or network IO.
Questions Why not scale up? Scaling up or out isn't immediate, by the time scaling completes the service may already have crashed. What about a load balancer? LBs will help, but it's indiscriminate: The LB doesn't know which clients and which operations are compute intensive.
Functional requirements
allowRequest(request)allowRequest(request)Non functional
- low latency
- accurate
- scalable
- high-availability (? Not so much)
- fault tolarance (? not so much)
- Usability: ease of integration and developer experience (great!)
Hint
Start with a simple solution first. Start with and mention a simple solution, and evolve.
Here's a simple first approach to this problem: 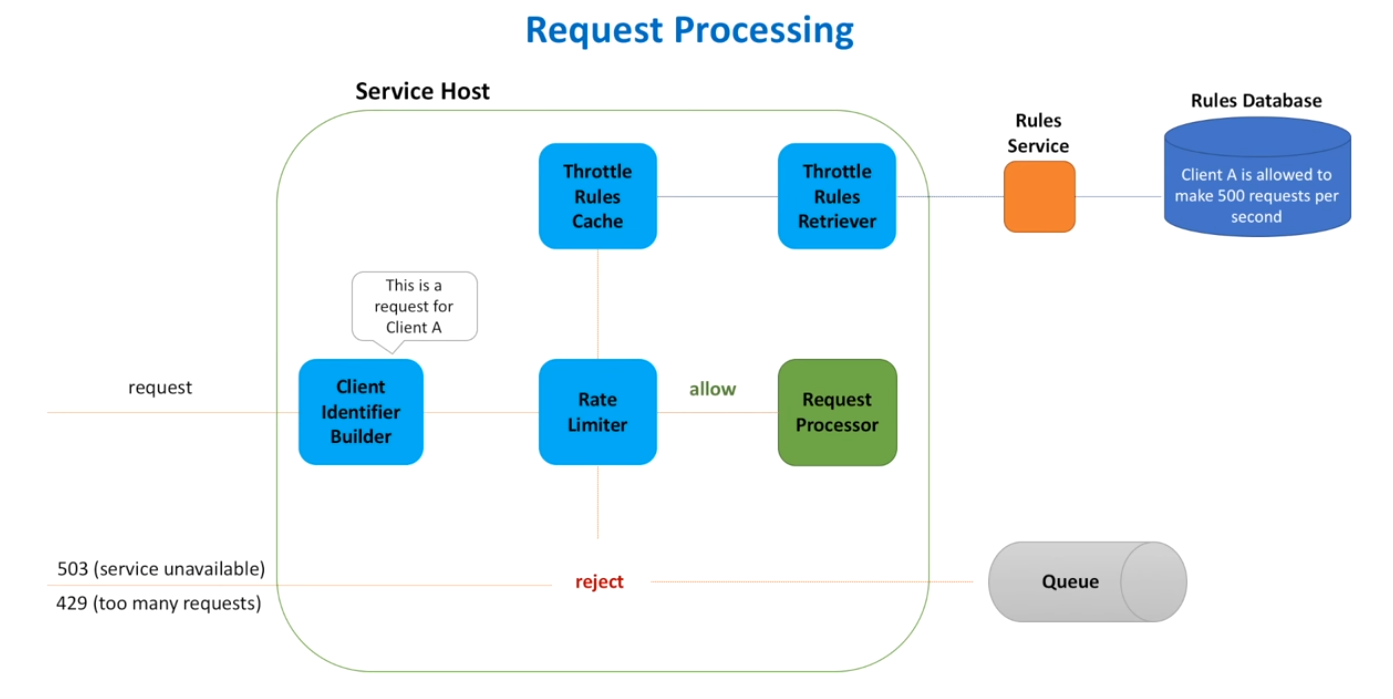
- interviewer may ask about rate limiting algorithm
- Token Bucket Algorithm
- bucket filled with tokens. This is the number of times a request can be made. Must know max, current, and refill rate of the bucket. Number of tokens never exceeds the max number of tokens.
- Token Bucket Algorithm
- interviewer might ask about defining the classes and interfaces for the library
- interview may ask about distributed service solution and how hosts shared data between each other
**the following image could be replaced by mermaid diagram 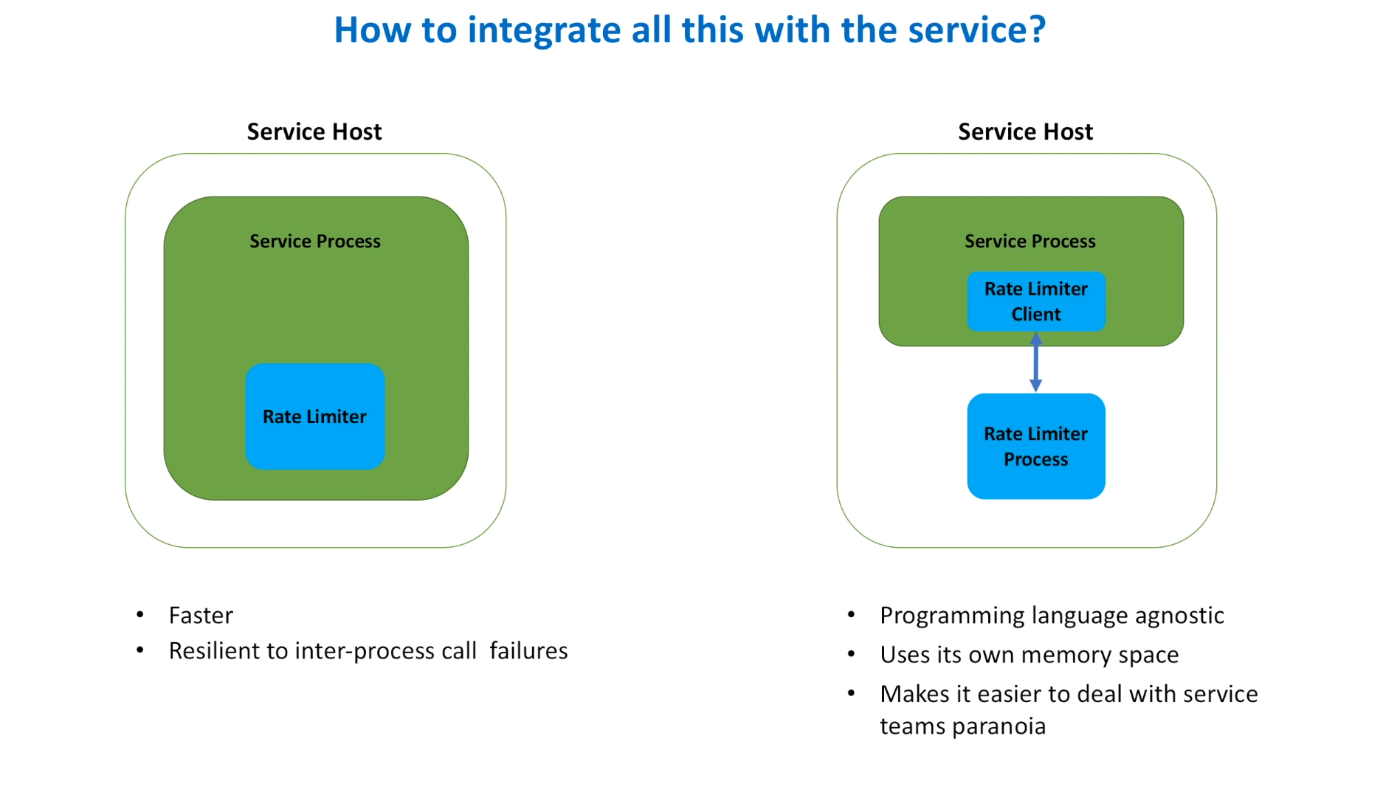 When we use a daemon to comms with other services in the cluster is a very common pattern.
When we use a daemon to comms with other services in the cluster is a very common pattern.
- If a request fails, use exponential backoff with jitter.
Distributed message queue
Problem: there are two services a producer and consumer, they need to communicate
What are the functional requirement? What is the scale? What are the non-functional requirements?
- Highly scalable
- Highly performant
- Highly available
- Durable so messages in the queue are not dropped
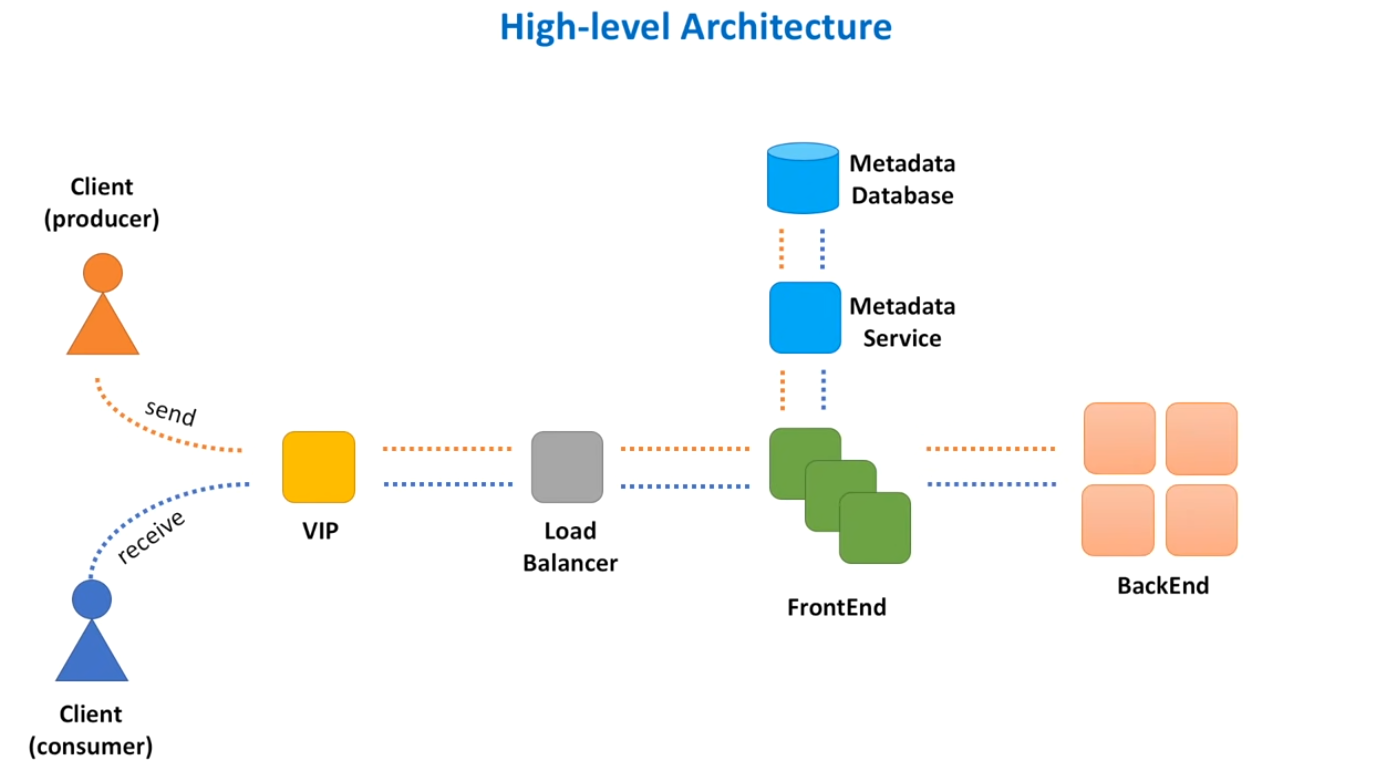
Think about push and pull model for consumers, do they request a message and get one if it's available? Or do they get notified if a new message is available?
Additional considerations:
- Security
- Monitoring
Notification Service
Problem statement: There is a publisher and subscriber. We want to create a service that sits between the publisher(s) and subscribers that can asynchronously coordinate message delivery between an arbitary number of publishers and subscribers.
Functional requirements
create_topic(topic_name) -> creates a new topic in the notification system
publish(topic_name, message) -> send message to notification system
subscribe(topic_name, endpoint) -> registers client to receive messages on `topic_name`create_topic(topic_name) -> creates a new topic in the notification system
publish(topic_name, message) -> send message to notification system
subscribe(topic_name, endpoint) -> registers client to receive messages on `topic_name`Non-functional
- Scalable
- Highly available
- Highly performant
- Durable
Architecture
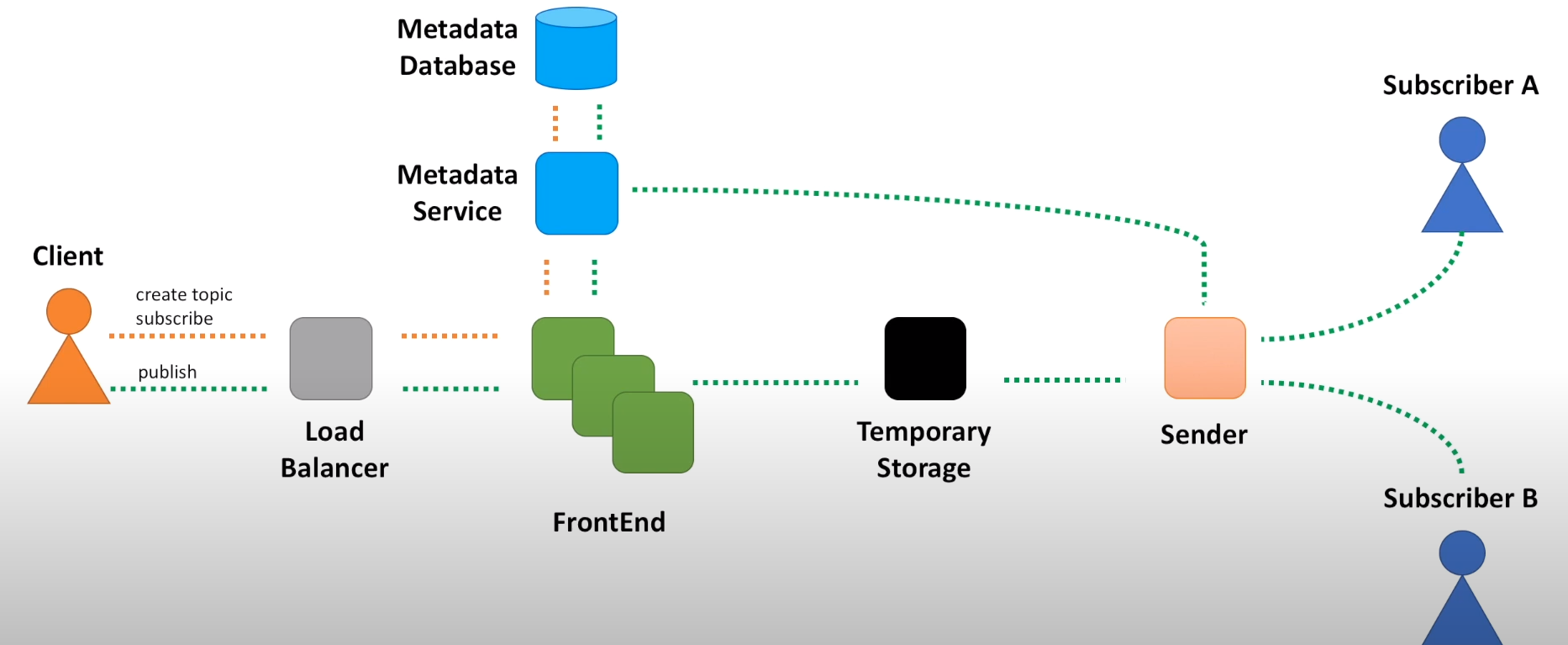
Frontend Service
- Lightweight web service
- Stateless service deployed across several data centers Actions:
- Request validation
- Authentication/authorization
- TLS termination
- Server-side encryption
- Caching
- Rate limiting
- Request dispatching
- Request deduplication
- Usage data collection
Front end service host
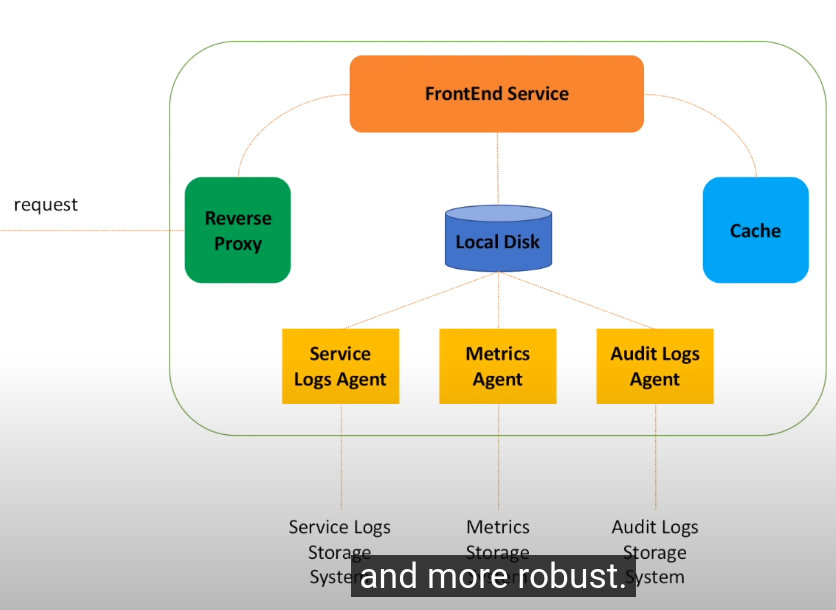
Metadata service
This is a distributed cache. It serves as a caching layer between the Frontend and persistent storage. 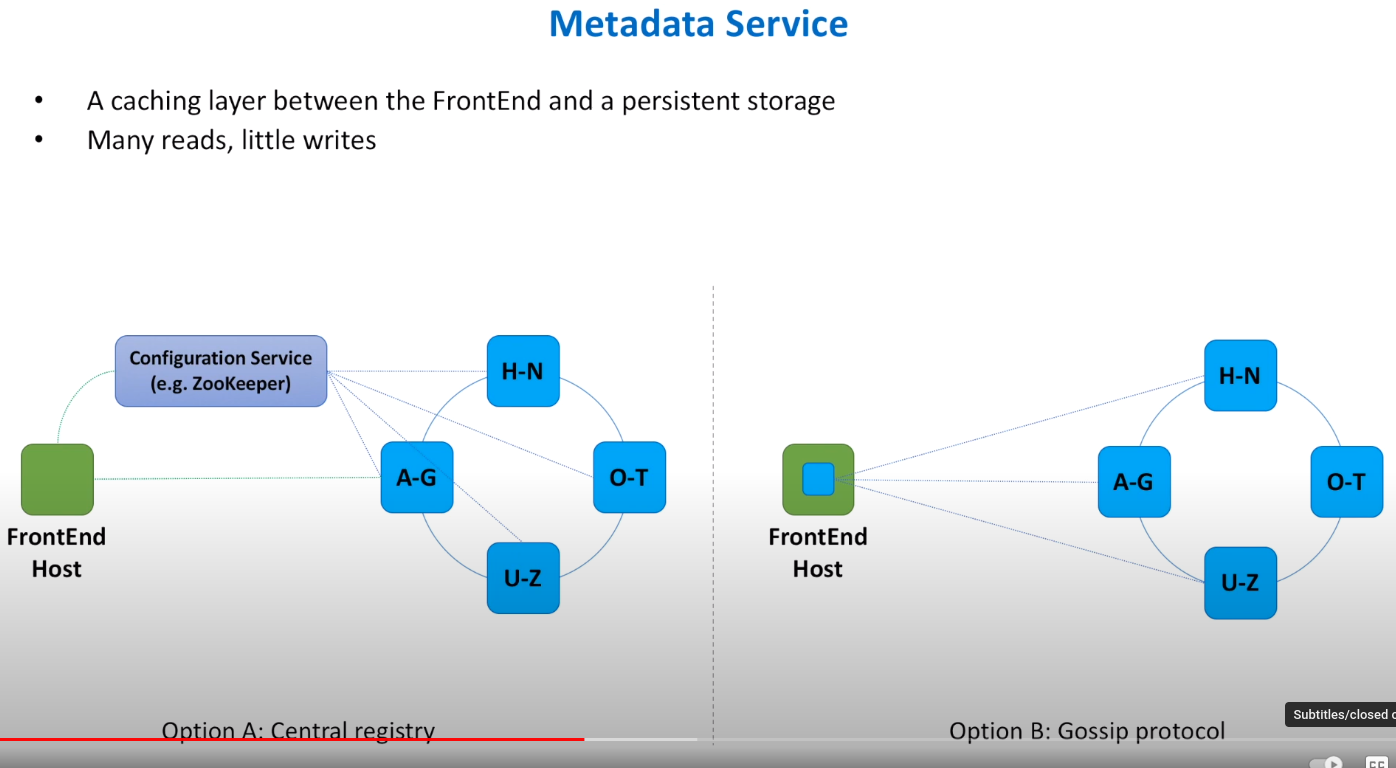

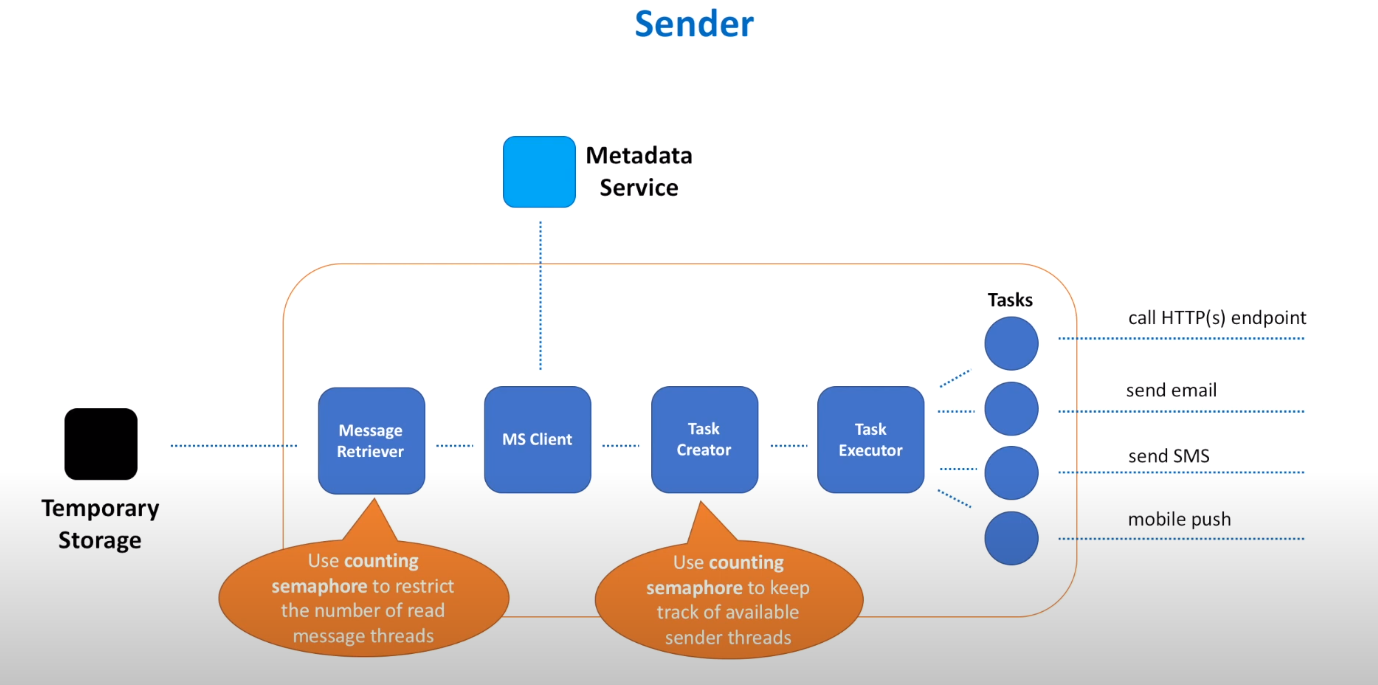
Sender
- The best solution is to use a dynamic thread pool that adjusts the number of worker threads available as more messages are retrieved. Use a counting semaphores for this process.
- Don't iterate over the list of subscribers and send synchronously, instead use a task-based system, with a task creator and executor, to send messages in parallel.